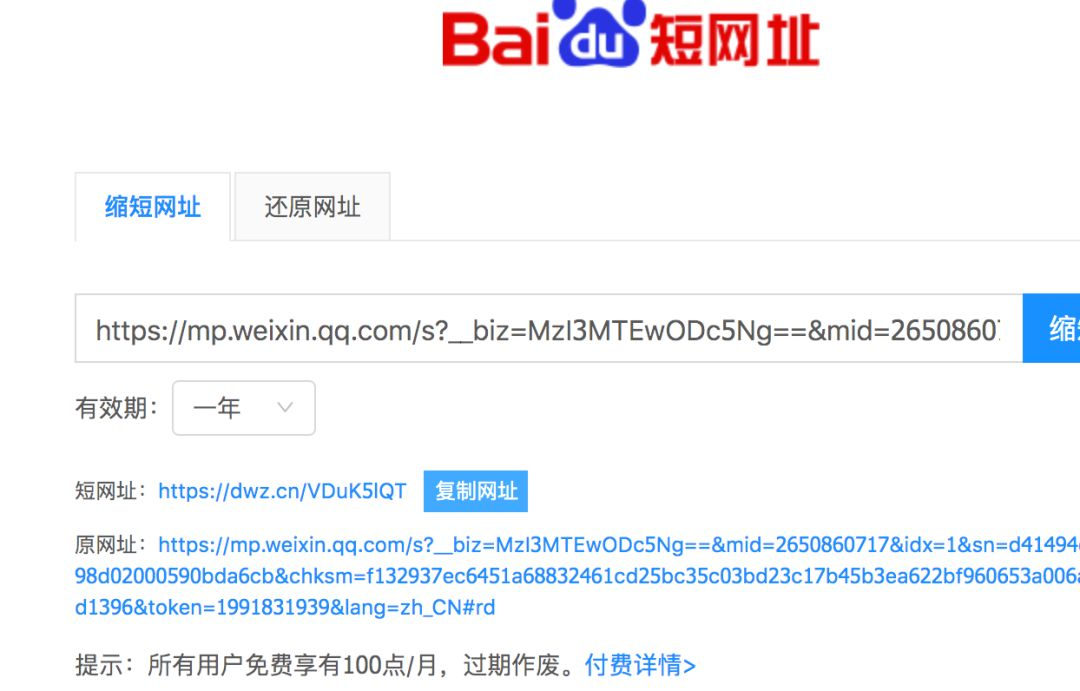
短链接服务,就是把一个长的URL转换成一个短的,相当于给原URL起了别名或者说 link。比如下面这个长网址,这么长:
https://mp.weixin.qq.com/s?__biz=MzI3MTEwODc5Ng==&mid=2650860717&idx=1&sn=d41494d71f3ef2298d02000590bda6cb&chksm=f132937ec6451a68832461cd25bc35c03bd23c17b45b3ea622bf960653a006a5e5d0f68d1396&token=1991831939&lang=zh_CN#rd
通过 dwz.cn 缩短后是这样:
https://dwz.cn/VDuK5lQT
无论是在显示、传输、打印甚至博文里都能节省更多空间,而且也便于
输入和记忆,这对于像Twitter、微博等限制内容的场合,或者在短信里需要包含网址时,短网址的优势就更加明显了。
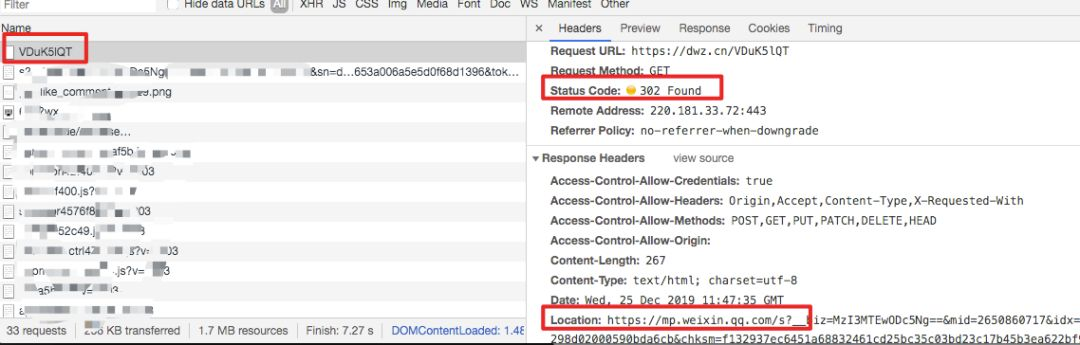
使用生成的短链接在浏览器里执行请求时,我们会发现经过一个302,最终跳转到原来的地址。
如果我们要开发一个类似的短链接服务,需要怎么设计,考虑哪些东西呢?
首先,咱们来理理需求:
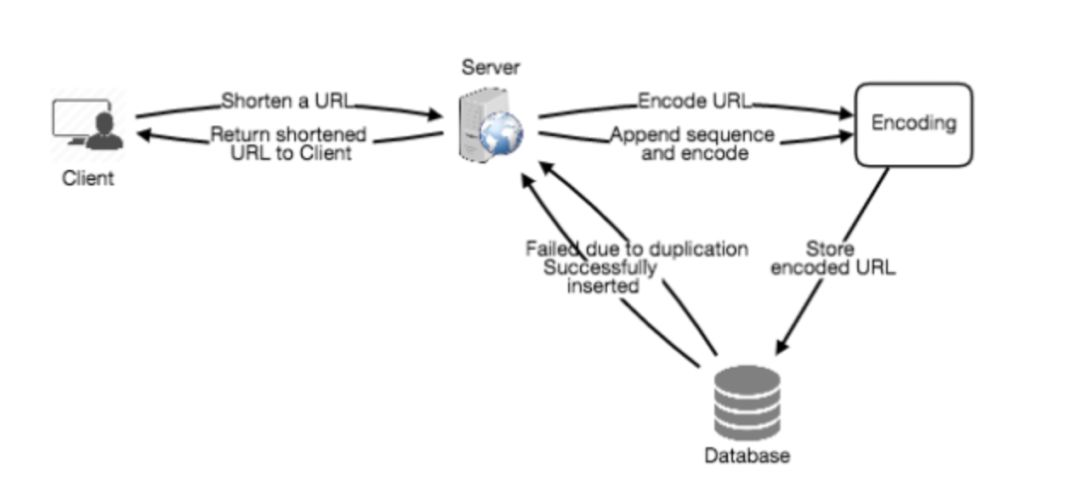
1. 我们的服务将指定的长URL,给其生成一个唯一的短URL。链接要够短方便复制、打印等。
2. 当用户输入短链接的时候,我们的服务需要将其重定向回原始URL
3. 用户可以指定短URL过期时间,在指定时间段之后短URL失效。
4. 判断用户是否有创建权限等等
参考上面百度短网址的界面设计,基本上上面咱们梳理的需求都覆盖到了。我们创建短网址的 API,输入参数应该包含这些:
返回值是一个短URL。
当然,为了防止服务被滥用,占用我们太多的存储,以及进行权限过滤,调用次数限制等,可以再增加一个accessKey, 这样只能申请过的用户才能访问。如果有记费需求也可以根据这个来限制。
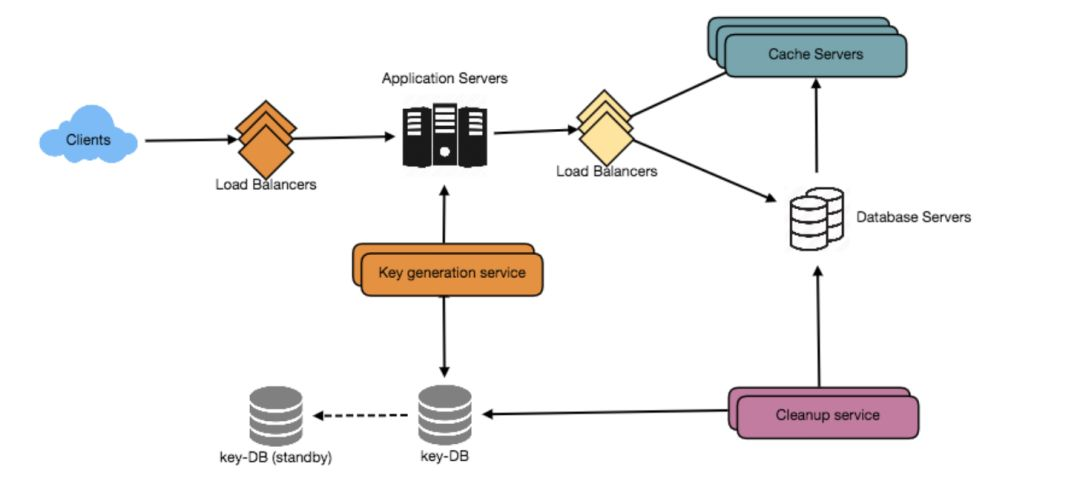
通过上面对于入参以及使用场景的预估,我们不难发现,相比生成短链接,这是个读请求重的系统。大部分的请求会是通过这些短URL,来获取原始内容,并进行跳转。所以从数据库到系统都要便于扩展。
设计
观察上面的短域名,我们应该不难发现在短域名之后,会有一个短码「VDuK5lQT」,这个是短域名的关键。这类似于咱们每个人的身份证号一样,通过它,来定位到原始的网址。
那后面这个关键的「短码」要怎么生成呢?
咱们想几种思路。
方式一:
能不能像关系型数据库的主键一样,自增然后使用?显然这里自增不行,自增增不出来字符串。同时每个DB自增也不能全局唯一,容易重复。但全局生成的思想可以使用。
类似于数据库多个DB通用的主键生成任务,这些通过一个第三方服务来生成Key的,一般称为 KGS (Key Generation Service),通过 KGS来生成随机位数的字符串。
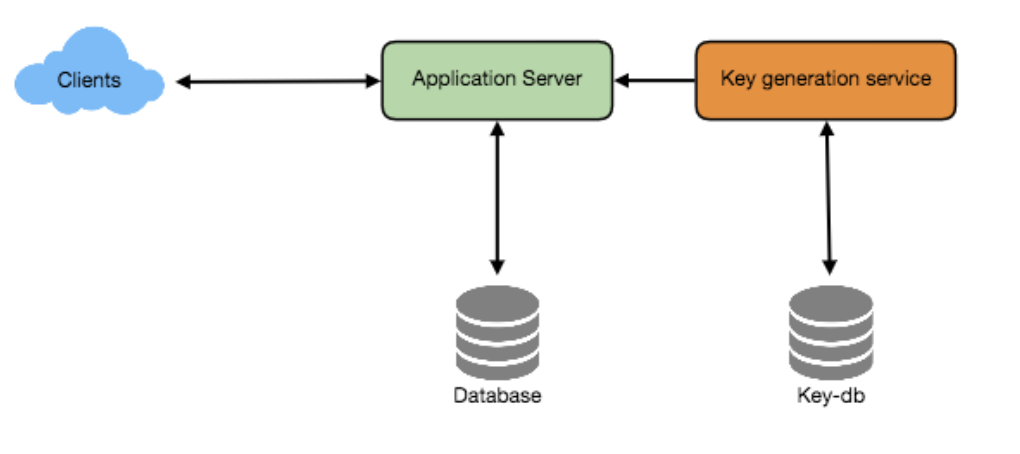
通过KGS 服务,随机生成特定位数的字符串,我们称之为key,然后把这些 key存储到数据库里备用。当收到生成短链接请求的时候,直接从备用的库里提取使用即可。这种方式更便捷和快速。
这里要需要注意 KGS 的高可用,别出现单点故障。
但对于预存在备用数据库的key,在并发请求的时候还是可能多个Server拿到相同的key。这时候就可以再新增个表,存放已经使用过的key。
每次使用过的key移动,新的只读待用表。或者KGS 提前预生成一些到内存或者缓存加速请求,在返回给各Server时要保证同步来解决重复问题。
也可以把这一部分工作解决给各个 Server, KGS 提供批量生成的功能,重复问题各个 Server 自己控制。
方式二:
可以通过给URL进行 MD5、Base64之类的计算,生成唯一的串。不过这些加密算法生成的串长度进比较长,我们仅需要6-8位,如果截断使用的话重复的机率也比较大。抖机灵的倒个序或者交换其中某几位的顺序也能降低重复的机率。
假设两个人输入了相同的长URL,这时会返回相同的短链接可能不太合适。对于此咱们可以增加个自增的数字。如果有重复再重新生成。
比较上面两种方式,方式一不仅不需要对URL进行编码,也不用担心生成的key重复和冲突,因为这一些都交给 KGS 来处理了,使用起来更方便快捷。
数据的复制和分区
为了方便数据库的扩容,我们需要进行分构,这样可以存储更多的数据。分区有这样几种方式:
Range Based
所有以字母'A'开头的短链在一个分区,字母'B'的在另一个分区,以此类推。这种查询和存储都比较简单,主要问题是可能分区不平衡,
有些分区数据多,有些少。
Hash Based
给每个短链接、key 或者原始链接进行Hash,再通过规则判断该值对应的数据存到哪个分区上。基于Hash的方式,如果遇到数据存储问题
可以通过「一致性Hash」的方式,进行数据的迁移等.
其他
为了加速请求,我们可以增加 Cache, 将更常用的URL加到缓存中,每次缓存未命中的时候将库中的数据更新到缓存中。
此外,也可以在Client 请求 Server的地方,在 Server 请求数据库的地方,以及 应用请求缓存的地方加上 LoadBalancer,将流量转到多个Server 上,支持更多的请求。
最开头的图里,短网址会有个短链接的有效期控制,我们可以通过一个后台任务来定期清理过期的链接,释放存储空间。
最终成型的设计:
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。







