《超级马里奥兄弟》你能玩到第几关?说起这款FC时代的经典游戏,大家可能再熟悉不过了,大鼻子、留胡子,永远穿着背带工装服的马里奥大叔,成为了很多80/90后的童年回忆。看着画面中熟悉的马里奥大叔一路跌跌撞撞,躲避半路杀出来的毒蘑菇,锤子乌龟,头盔兔子、食人花,感觉又回到了小时候。
最早发行的这版《超级马里奥兄弟》设置8个场景,每个场景分为4关,共32个关卡,相信很多朋友至今还没有完全通关。
Viet Nguyen就是其中一个。这位来自德国的程序员表示自己只玩到了第9个关卡。因此,他决定利用强化学习AI算法来帮他完成未通关的遗憾。
现在他训练出的AI马里奥大叔已经成功拿下了29个关卡。

不过,遗憾的是第4、7、8场景中的第4关卡未 通过。Viet Nguyen解释说,这与游戏规则的设置有关。在一场游戏结束后,玩家可以自行选择通关路径,但这可能出现重复访问同一关卡的情况,所以AI未成功进入到这三关游戏之中。
Viet Nguyen使用的强化学习算法正是OpenAI研发的近端策略优化算法(Proximal Policy OptimizaTIon,简称PPO),他介绍,此前使用A3C代码训练马里奥闯关,效果远不及此,这次能够达到29关也是超出了原本的预期。
现在Viet Nguyen已经将基于PPO编写的完整Python代码发布到了Github上,并给出了详细的使用说明,感兴趣的朋友可以体验一下:

Github地址:https://github.com/uvipen/Super-mario-bros-PPO-pytorch
还会玩Dota的AI算法:PPO
据了解,PPO是OpenAI在2017年开发的算法模型,主要用来训练虚拟游戏玩家OpenAI Five,这位虚拟玩家在2018年的Dota2人机对抗赛中,战胜过世界顶级职业选手,同时能够打败99.95%的普通玩家。
复杂的游戏环境一直被研究人员视为AI训练的最佳场景。为了让AI掌握游戏规则,学会运用策略,强化学习是研究人员常用的机器学习方法之一,它能够描述和解决AI智能体(Agent)在与环境交互过程中通过学习策略实现特定目标的问题。
近端策略优化算法(PPO)已成为深度强化学习基于策略中效果最优的算法之一。有关该算法的论文已经发布在arXiv预印论文库中。
 论文中指出,PPO是一种新型的策略梯度(Policy Gradient)算法,它提出新的“目标函数”可以进行多个训练步骤,实现小批量的更新,解决PG算法中步长难以确定的问题。固定步长的近端策略优化算法如下:
论文中指出,PPO是一种新型的策略梯度(Policy Gradient)算法,它提出新的“目标函数”可以进行多个训练步骤,实现小批量的更新,解决PG算法中步长难以确定的问题。固定步长的近端策略优化算法如下:

(每次迭代时,N个actor中的每个都收集T个时间步长的数据。 然后在这些NT时间步长的数据上构建替代损失,并使用 minibatch SGD 进行K个epochs的优化。)
研究人员表明,该算法具有信任区域策略优化(TRPO)的一些优点,但同时比它实施起来更简单,更通用,具有更好的样本复杂性(凭经验)。为了证实PPO的性能,研究人员在一些基准任务上进行了模拟测试,包括人形机器人运动策略和Atari游戏的玩法。
PPO算法的基准任务测试
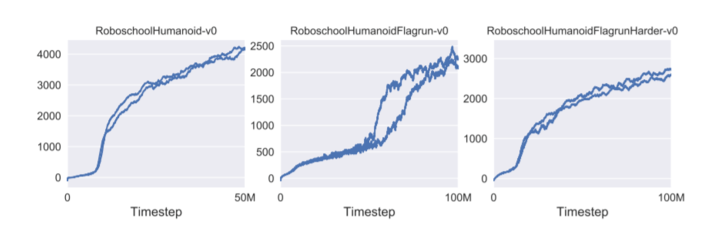
在游戏角色的AI训练中,一种基本的功能是具备连续性的运行和转向,如在马里奥在遇到诸如地面或者空中障碍时,能够以此为目标进行跳转和躲避。论文中,研究人员为了展示PPO的高维连续控制性能,采用3D人形机器人进行了测试,测试任务分别为:
(1)仅向前运动;(2)每200个时间步长或达到目标时,目标位置就会随机变化;(3)被目标击倒后,需要从地面站起来。以下从左至右依次为这三个任务的学习曲线。
研究人员从以上学习曲线中,随机抽取了任务二在某一时刻的性能表现。如下图,

可以看出,在第六帧的放大图中,人形机器人朝目标移动,然后随机改变位置,机器人能够跟随转向并朝新目标运行。说明PPO算法在连续转控方面具备出色的性能表现。
那么它在具体游戏中“获胜率”如何呢?研究人员运用Atari游戏合集(含49个)对其进行验证,同时与A2C和ACER两种算法进行了对比。为排除干扰因素,三种算法全部使用了相同的策略网络体系,同时,对其他两种算法进行超参数优化,确保其在基准任务上的性能最大化。
可以看出,在第六帧的放大图中,人形机器人朝目标移动,然后随机改变位置,机器人能够跟随转向并朝新目标运行。说明PPO算法在连续转控方面具备出色的性能表现。
那么它在具体游戏中“获胜率”如何呢?研究人员运用Atari游戏合集(含49个)对其进行验证,同时与A2C和ACER两种算法进行了对比。为排除干扰因素,三种算法全部使用了相同的策略网络体系,同时,对其他两种算法进行超参数优化,确保其在基准任务上的性能最大化。
如上图,研究人员采用了两个评估指标:(1)在整个训练期间每集的平均获胜数;(2)在持续100集训练中的每集的平均获胜数。 前者更适合快速学习,后者有助于最终的比赛表现。可以看出PPO在指标一种的获胜次数达到了30,在小样本下有更高的胜率。
最后研究人员还强调,PPO近端策略优化的优势还在于简洁好用,仅需要几行代码就可以更改为原始策略梯度实现,适用于更常规的设置,同时也具有更好的整体效果。
本内容属于网络转载,文中涉及图片等内容如有侵权,请联系编辑删除
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。









{kind=link}